Top 10 IT companies in Dehradun
Posted on March 12, 2026
![Difference Between Bagging and Boosting [Only Guide You Need]](https://www.helpingcontent.com/wp-content/uploads/2025/12/Difference-between-Bagging-and-Boosting.png)
When people start learning machine learning, they often feel confident in the beginning. But the moment topics like bagging and boosting show up, things suddenly feel complicated.
The names sound technical, explanations online feel rushed, and most articles assume you already know a lot.
This creates a real problem. If you don’t clearly understand these concepts early on, everything that comes later starts to feel confusing too. You may memorize definitions, but you won’t really get why or when to use them.
In this blog, we’ll understand what bagging and boosting is in machine learning and also learn the difference between bagging and boosting with real examples.
By the end you’ll know what they are, how they work, how they’re different, and when each one actually makes sense to use.
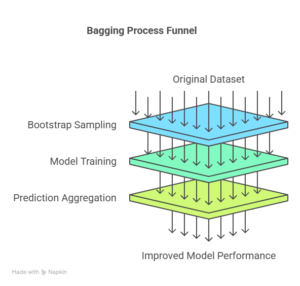
Bagging stands for Bootstrap Aggregating, which is a method used to improve the performance of a machine learning model by using multiple models instead of just one.
Normally, when we train a model, it learns from the data and gives predictions. But a single model can be unstable. Small changes in data can lead to very different results. This is where bagging helps.
Each model looks at the problem slightly differently, and when they all agree on something, the result is usually more reliable.
It takes the original dataset and creates multiple random samples from it. These samples are created in a way that some data points may appear more than once, while others may be missing. This is completely normal.
And then we train separate models on each of these samples. Using the same algorithm at the same time without knowing about each other
After training, each model makes its own prediction we combine these predictions: If it’s a classification problem, we use voting, If it’s a regression problem, we use averaging
The idea is simple: one model may make mistakes, but many models together usually make fewer mistakes.
The most famous example of bagging is Random Forest. A Random Forest creates many decision trees. Each tree is trained on a different random sample of data.
When a new input comes in, every tree gives its opinion, and the forest chooses the final answer based on majority voting.
Real Life Example:
If one person makes a wrong judgment, it’s risky.
If 100 people independently give the same answer, it’s much safer.
That’s the simplest example for bragging.
Bagging offers several practical benefits like, it reduces overfitting. Models like decision trees tend to overfit easily, and bagging smooths this out.
It also improves prediction stability. The model becomes less sensitive to small data changes. Third, it works very well with models that are naturally unstable.
Last but not least, bagging allows parallel training, which means it can be faster when enough computing power is available.
Some commonly used bagging-based algorithms are:
All of these follow the same core idea: train many independent models and combine their outputs.
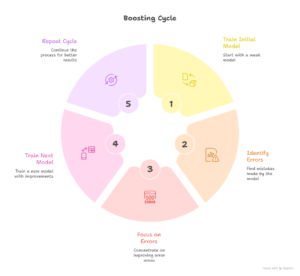
Boosting takes a very different approach. Instead of training models independently, it trains models one after another. Each new model learns from the mistakes made by the previous ones.
In simple words, boosting is about gradual improvement. It starts with a weak model, checks where it fails, and then focuses more on those failures in the next model.
In Boosting, a model is trained on the dataset. It makes predictions, and some of them are wrong. Then, the data points that were predicted incorrectly are given more importance.
After that a new model is trained. This model pays extra attention to those difficult data points. This process continues multiple times.
Each model tries to correct the errors of the previous ones. In the end, all models are combined to form a strong final model.
So instead of many independent opinions, boosting creates a learning chain.
One of the earliest boosting algorithms is AdaBoost. It increases the weight of misclassified data points so future models focus on them more.
Another popular example is Gradient Boosting, where each model improves predictions step by step.
Modern versions like XGBoost and LightGBM are optimized versions of boosting that are widely used in real-world projects.
That’s why boosting algorithms are often used in competitions and production systems.
Here are some of the popular boosting algorithm that you may consider
Each one follows the boosting idea with slight improvements.
| Basics | Bagging | Boosting |
| Core Idea | Combines many independent models | Builds models step by step |
| Training Style | All models train at the same time | Models train one after another |
| Model Dependency | Models do not depend on each other | Each model depends on the previous one |
| Main Goal | Reduce overfitting | Improve learning accuracy |
| Error Handling | Errors are averaged out | Errors are directly corrected |
| Data Treatment | All data points are treated equally | Hard-to-predict data gets more focus |
| Noise Handling | Works well with noisy data | Sensitive to noisy data |
| Speed | Faster due to parallel training | Slower due to sequential training |
| Common Algorithm | Random Forest | XGBoost / AdaBoost |
| Best Use Case | High-variance models | Weak models needing improvement |
Here is the video guide that will help you to under the difference between bagging and boosting techniques very easily.
Use Bagging when:
Use Boosting When:
Hope you learned the real and in-depth difference between bagging and boosting algorithm and now you realize that they are not complicated once you understand their mindset.
Bagging is about multiple independent opinions coming together. Boosting is about learning from mistakes step by step.
Neither is better in all cases. The right choice depends on your data and your problem. Once you understand how they think, choosing between them becomes much easier.
Neither is always better. Bagging is great for stability and noisy data, while boosting shines when you want higher accuracy on clean data. The better choice depends on your problem and dataset.
Scikit-learn provides strong, easy-to-use implementations of both bagging and boosting, making it a popular choice for beginners and professionals alike.
Bagging is usually faster because models can train in parallel. Boosting takes more time since each model depends on the previous one.
Helping content is a content write who loves to right about the Technology, Home Decor, and Sprituality. When he is not writing he might be doing skydiving.

Posted on March 12, 2026

Posted on March 11, 2026

Posted on February 13, 2026